Trust, assurance and levels of security (advanced)¶
Because trust is usually something psychological, it is easy to forget that it is also an important concept and mechanism in cyber and information security. Trust is of course mostly visible outside these areas, but if security is considered broadly through the concept of dependability, one realises that most of our everyday life depends on trust. Dependability means that we can base our actions on the actions of other parties (‘depend on them’). The concept may be seen as a special case of integrity, but it can also be thought to encompass all of security. Trust is psychological because individuals feel it, but it is also social because it is “felt” collectively. As a brief definition, trust can be described as belief in the future or a willingness to accept uncertainty.
There is extensive literature on the factors affecting people’s trust in various online situations, such as electronic commerce. A relatively early article on this topic is by Wang and Emurian (2005), and the link leads to more recent articles citing this publication (over 1100 as of 2026).
Mapping and categorising trust (advanced)¶
The first concept map below presents some general characteristics of trust, while the second delves deeper into the domain of information security. As a transition from the general to the specific, here is a list of contexts in which the concept of trust typically appears in computing:
- You may trust the sender of an email or other message and then open, for example, an attached document. You are well aware of what can go wrong here and how an attacker might attempt to make this happen. In all the other points on this list, too, you can examine the role of trust from the attacker’s perspective.
- Whitelist: a list of entities regarded as trustworthy and granted permissions.
- Certificate policy determines, among other things, how thoroughly the owner of a public key must be validated before issuing a certificate. There are many quality criteria, but the following is a very common arrangement.
- Websites may have ordinary public key certificates or EV certificates. EV stands for extended validation, meaning that the certificate issuer (CA) has performed a specific type of validation regarding the key owner’s identity. “Ordinary” certificates also have levels: DV, OV, and IV refer to domain-, organisation-, and individual-validated certificates.
- Web browsers and other software come with pre-installed certificates from multiple CAs. The browser acts as a trust anchor for the user, who first extends trust to these CAs, then to the certificates they issue, then to the connection secured by the certified key and, in most cases, also to the website operating under such protection. The last step is not justified.
- eIDAS stands for Electronic Identification and Trust Services Regulation (910/2014/EU). eIDAS levels of assurance, namely low, substantial, and high, represent different degrees of trust in a claimed identity. The link allows you to check what each level may require.
- Certification authorities are only one example of trust services. In general, such services aim to be competent and reliable in issuing (selling) statements about an object so that it can be trusted in a specific respect. A certification authority does this for a key, certifying that it belongs to a particular website or person. Another type of trust service is a bank, which certifies a person’s identity.
- Trusted Introducer is a support infrastructure created by the European CERT community for CSIRT actors. Each CSIRT (Computer Security Incident Response Team) is a kind of crisis response unit (maintained by a company, authority, or service provider). Admission requires trust, since communication between teams concerns attacks.
- The Trusted Computing Base (TCB) is a concept from the 1980s and thus very fundamental. It refers to the part of an information system where the security policy applies without additional checks, meaning all accesses are legitimate. This is somewhat theoretical, however, since the TCB may also contain software or hardware errors. In practice, the TCB is what we must trust in order to build more advanced system features.
- The Trusted Platform Module (TPM) is a more recent incarnation of the TCB, developed by the Trusted Computing Group. TPM may appear under different names, such as Embedded Security Subsystem.
- Trusted path is a term referring to the user’s way of reaching the trusted base, i.e. the TCB. In a sense, the entire path—for example from keyboard through drivers and command interpreter to the operating system kernel—becomes part of the TCB.
Artificial intelligence, blockchains, computational trust (advanced)¶
This section deals with trust, but approaches it through several detours, such as artificial intelligence, leading to trust levels related to recommendations, reputation, and computational trust. Note that the EU AI regulation, the AI Act, has already been discussed in an earlier section, and the content of the current section is worth reflecting against it as well. AI plays only a supporting role here.
Before the current era of ubiquitous AI, blogger and CISO Rob Bainbridge advocated a role for machine learning as a supporter of trust and an addition to the security–usability dimension (2018): “Trust is the fundamental part of control and can be heavily exploited using contextual and behavioural analysis to both improve user experience and increase security effectiveness.”
The better-known blogger Bruce Schneier would likely have opposed this, based on his earlier essays on trust. One of them (February 2019) discusses blockchains, but also contains broader reflections on trust. A somewhat more recent commercial essay by EY (2020) provides an example of blockchain use in generating trust within the Xbox ecosystem. The main theme of the essay is how regulators and companies at the time viewed trust in AI (that is, AI as an object of trust, not as its tool). Another blockchain example concerns the cold chain of fish delivery in an article on automating trust (PwC, 2019.
Schneier’s critical perspective has become even more pronounced with the rise of generative AI, and he has written about trust and AI, for example, in 2025.
Cybersecurity professionals likely have an interesting role in helping people trust AI, but that trust involves much more than potential improvements in security. It suffices to consider algorithms in autonomous vehicles, military systems, social media, and search engines. Nevertheless, examining trusted intelligence in another EY article (2020) brought at least part of the AI hype back to basic information security: to reduce the need for trust, attribute-based access control (ABAC) applies the need-to-know principle with finer granularity than role-based access control (RBAC). The difference between RBAC and ABAC can be illustrated with a kitchen analogy: a chef and a cleaner are different roles, but if both roles have access to the kitchen, both have access to chilli peppers. ABAC would distinguish further, preventing even the chef from accessing them if the current recipe (= set of attributes) does not include peppers.
Before applying AI, cybersecurity professionals should understand levels of trust in the same way they approach risks. You have already encountered the problem of assessing and even understanding probability if you have studied risk management in a previous module. Suppose that risks have been managed and appropriate security mechanisms are in place. How certain are you that things “will be fine”?
To achieve certainty, you also need assurance that the security mechanisms function correctly. You likely did not create all of them yourself, so you must rely on the work of others. It is beneficial if designers and manufacturers have followed best practices and design principles for security. You need multiple layers of trust to be assured that this is the case. Influencing factors include organisational practices at the designer’s workplace, the designer’s education, and the standards of the institution they attended. Security audits usually extend only to the first of these. Thus, you cannot eliminate the psychosocial aspects of trust, such as those mentioned on the left side of the first map. Perhaps some of these aspects may one day be embedded in AI, and hopefully AI will then be trustworthy. The need for the AI Act suggests that the time has not yet come—or at least not for all publicly available AI applications.
If you aim for maximum assurance, you can build upon the aforementioned TPM modules. In addition, you can use zero trust architecture mentioned in the second map, by verifying all requests and minimising domains.
If you are not fully certain, instead of zero trust you may partially restrict access—to improve user experience within the system. Continuing the kitchen analogy, you might check whether chefs are healthy and sober, have washed their hands, have protected their hair, are possibly acting on behalf of another chef, or whether a fully trusted chef is present. If something is not entirely in order, the most valuable or dangerous ingredients can be withheld. In the same way—more realistically—levels of trust can be applied in security technology. In any case, certain assurance measures are used to increase the likelihood that trust is not misplaced—or not excessive. If there are different levels of trust, access rights are also granted at different levels.
Trust evaluated “at runtime”, especially at different levels, is called computational trust, and the calculations are part of trust management. This is a very popular field of research (and business). The survey article by Ruan and Durresi (2016) is a suitable starting point for entering the topic and finding recent publications (117 as of May 2026).
Maps (advanced)¶
The first map mainly shows entities, that is, subjects and objects, between which a trust relationship can be formed. Note that when a process authenticates a human user, system, or device, it can be said to trust these entities. However, if nothing beyond authentication is involved—even with extensive mathematics—such trust is not computational, and certainly not calculated in the sense of speculative.
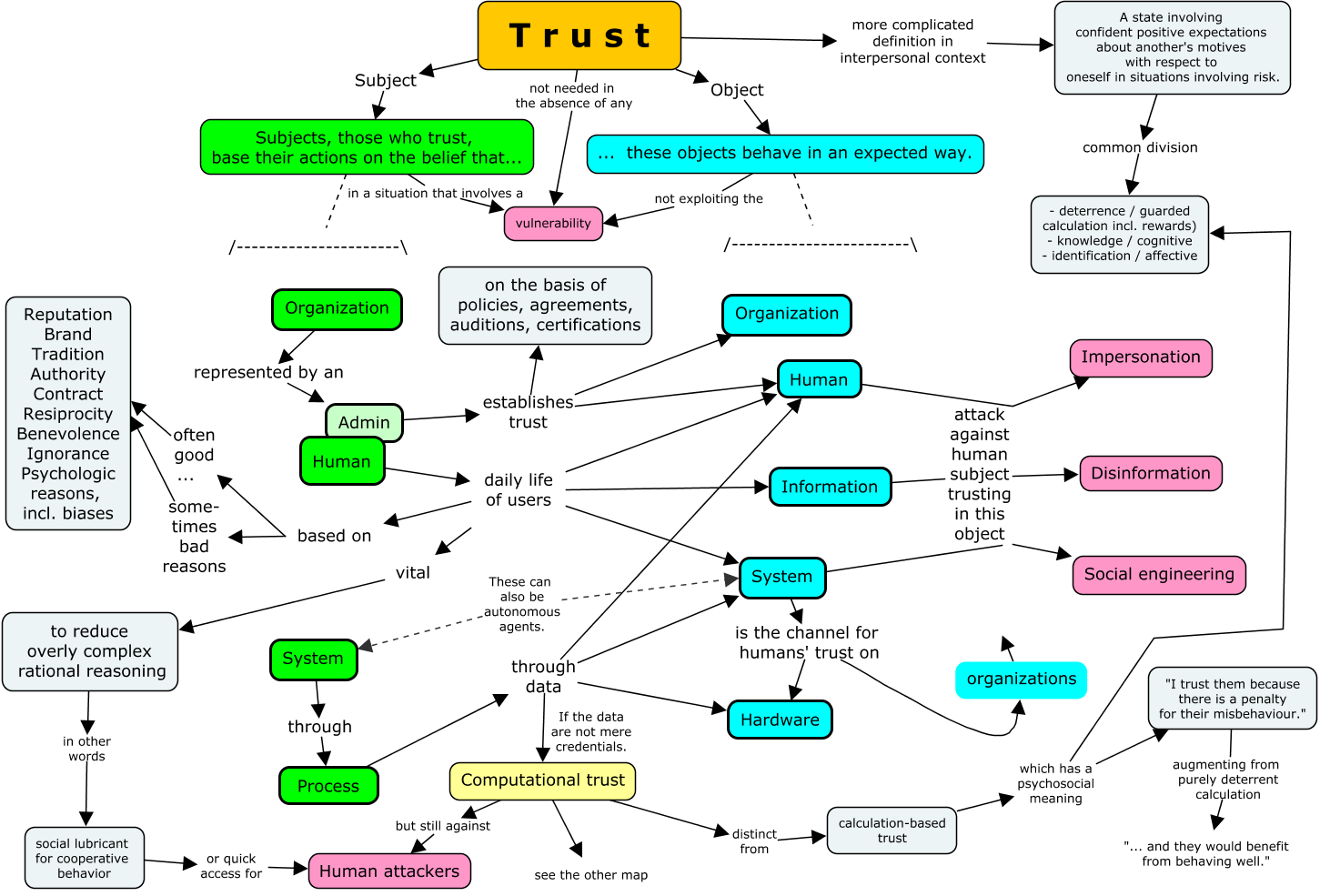
The second map also starts with subjects and objects in the upper left corner, but proceeds through the data owner to the use of data. In the middle, it highlights trust required where not everything can be verified. This map does not show attacks, but one must always remember that most nodes conceal some potential attack vector.
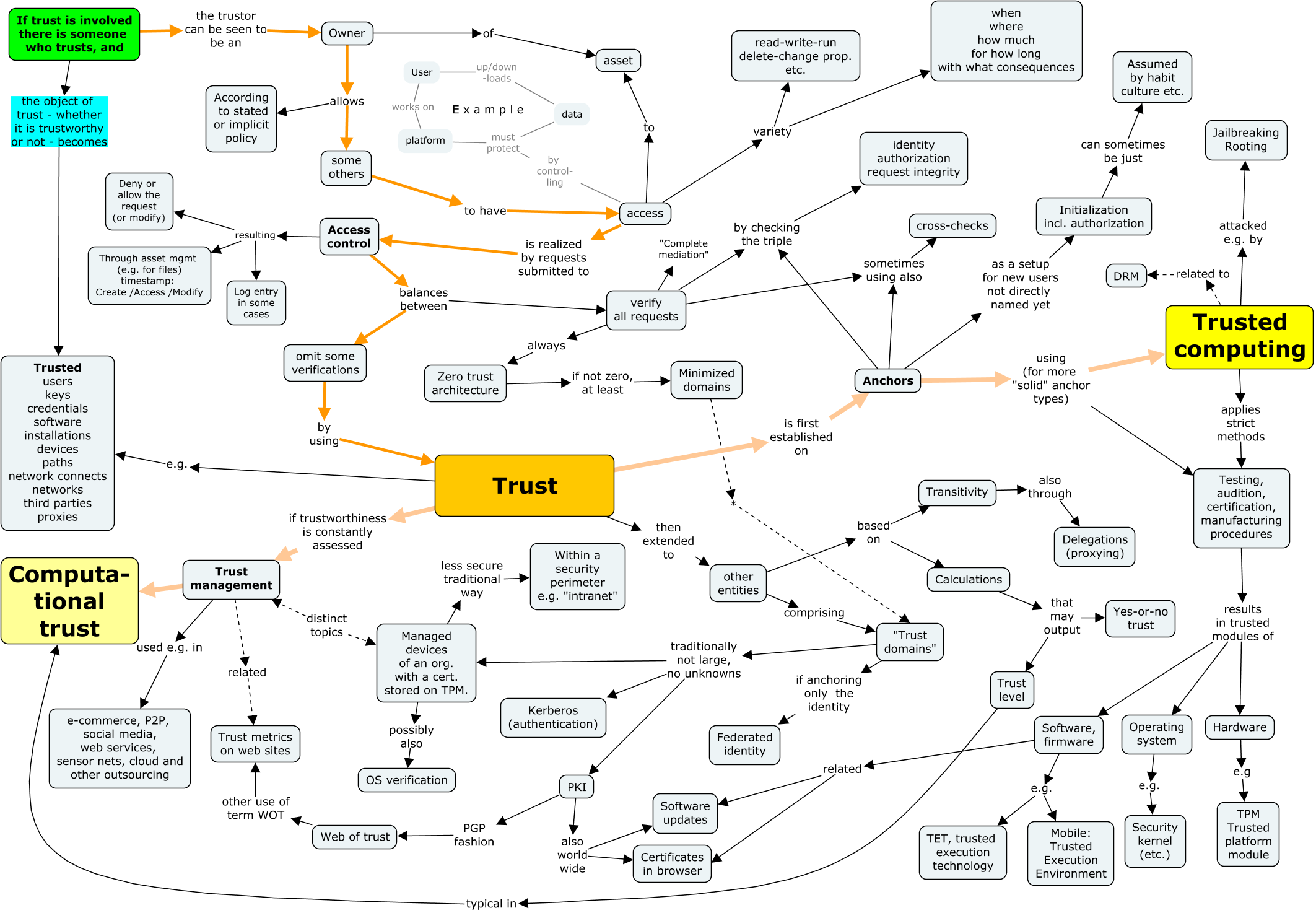
Note on the accessibility of concept maps