Monitor: data sources¶
From a continuous stream of data, the objective is to detect and localise in real time attempts to compromise ICT infrastructures. This is achieved by collecting traces of different operations from multiple sources, describing either the behaviour of a host or system (operating system, applications) or the behaviour of the network (traffic and communication).
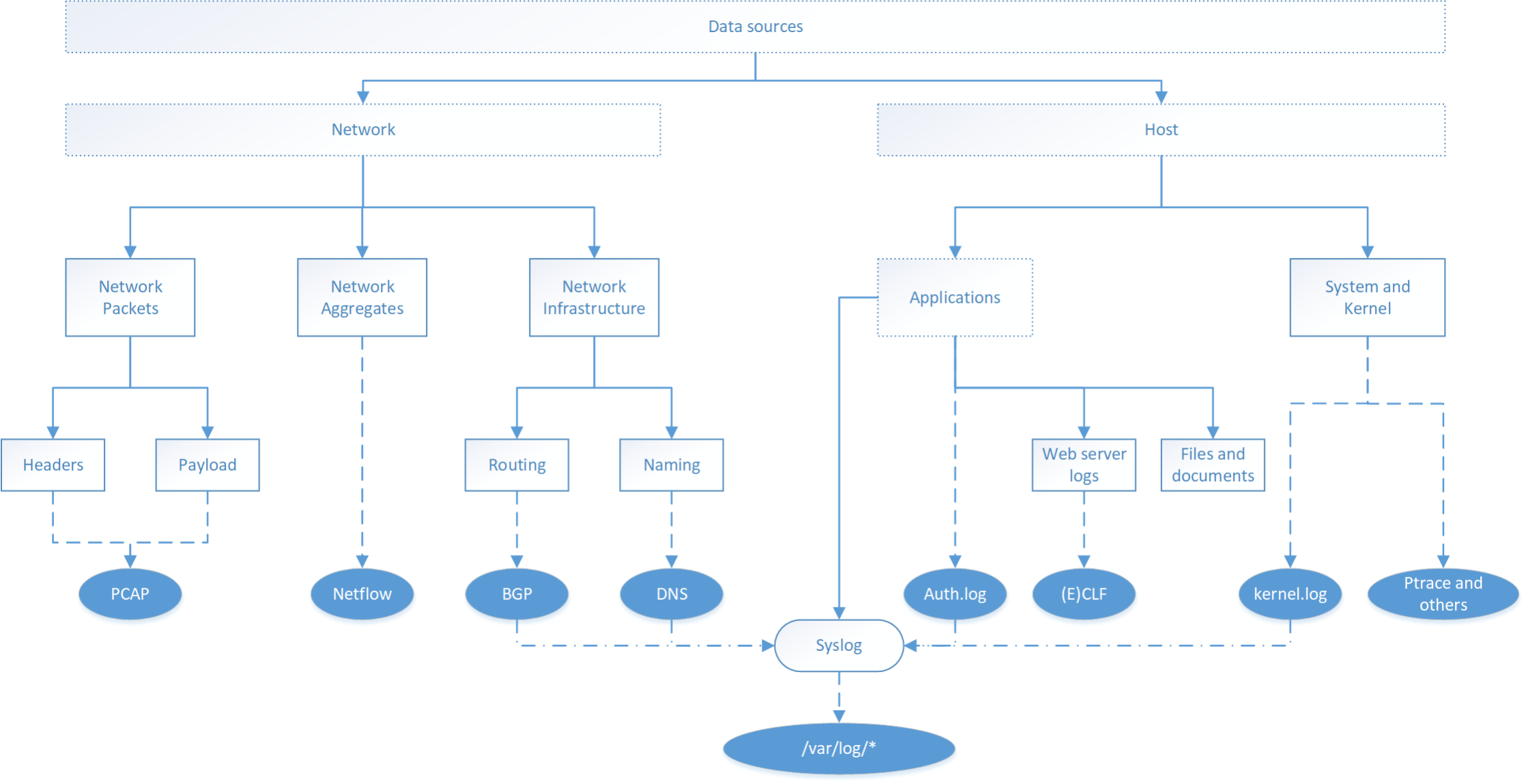
The figure presents a simplified conceptual view of possible data sources. Rectangles represent concepts. Ovals represent concrete implementations of these data sources. The rounded rectangle represents the standardised format Syslog, which has a particular role. It supports log inputs from network devices, operating systems, and applications. The concepts and implementations shown in the figure are discussed in more detail in the advanced sections of this module.
Data sources are event streams and traces of activity left by system users in services. Data sources feed information to IDPS sensors, which generate alerts. Alerts represent information of security interest. In general, an event or stream of events acquired by a sensor generates an alert that synthesises the security issue found by the sensor.
Moving to external resources, such as Internet or cloud service providers, may limit the availability of some data sources for practical reasons (for example volume, privacy constraints, or the mixing of data from multiple customers in the same trace). It is also possible that traces from host environments are compromised by attackers or made available without the customer’s knowledge or consent.
Network traffic (advanced)¶
Network data has become the de facto standard input for intrusion detection systems, because of the overall reliance on networks and the ease of use of standard formats. Packet capture is the most common way to collect network traffic. Network data is not always available internally, however, and it may be necessary to obtain information from Internet service providers, for example to identify attackers’ addresses and routes.
The most common type of network traffic data is the full packet capture, exemplified by the libpcap library and the tcpdump and Wireshark applications. The popular pcap library is available in many environments and is distributed as open source software. Numerous data sets have been made available or exchanged privately in pcap format for almost as long as intrusion detection research has existed. Packet capture data is not, however, stored on IDPS sensors, because retaining pcaps requires a vast amount of storage space. Pcap files are therefore often reserved for research data sets or forensic purposes. Network-based IDPS sensors may have the capability to store a few packets together with an alert. Typically, the packet that triggered the detection and a few others belonging to the same context (TCP, etc.) and appearing shortly afterwards are stored. This capability is usually limited to misuse detection.
The pcap library requires a network interface that can be configured into promiscuous mode. This means that the interface captures all packets on the network, including those not addressed to it. Also, there is no need to bind an IP address to the network interface to capture traffic; leaving it unbound is recommended to avoid interference. Due to these properties, packet capture can usually take place silently and invisibly, and is not detectable by default.
Aggregating network traffic: NetFlow (advanced)¶
Packet captures are inconveniently large in size, yet there is a need for an overall view of network activity. Network aggregates address this problem. They are mechanisms that count packets sharing certain attributes (source, destination, protocol, or interface). These calculations are performed by network devices as packets cross their interfaces.
NetFlow is a widely used network monitoring tool for detecting and visualising security incidents in networks. The NetFlow protocol records counters of packet headers passing through routers. NetFlow was developed by Cisco and has been standardised as IPFIX in RFC 7011.
Because NetFlow is developed by network device vendors, it integrates very well with the network. Its strongest use cases include visualising network communications and relationships and highlighting communication patterns. Visual analytics provides a user-friendly way to understand anomalies and their impacts, which is why NetFlow is also widely used in cybersecurity tasks.
NetFlow can, however, suffer from performance degradation in both computation and storage. Processing packets to compute NetFlow counters requires access to the router’s CPU, significantly reducing the performance of network devices. Modern routers can now generate NetFlow records in the hardware layer, which reduces the performance impact.
In the past, operators often used NetFlow in sampling mode (for example, analysing only one packet out of a thousand) to limit the impact on CPU performance. This results in a limited view of traffic, and many security incidents may go unnoticed. With the exception of large denial-of-service attacks, relying solely on sampled NetFlow data for security is difficult.
Internal information from network infrastructure (advanced)¶
Network infrastructure uses many protocols to ensure correct communication. Two of these—naming and routing infrastructure—are also of interest for both attacks and detection. Reporting on routing or naming operations requires direct access to the infrastructure view. Operators involved in routing and naming typically rely on Syslog for data collection.
DNS protocol and naming (advanced)¶
DNS (domain name system) is one of the most important services on the Internet. It translates domain names into IP addresses (for example, www.tuni.fi -> 130.230.252.62). Naming is also required by TLS (RFC 8446) and by certain HTTP mechanisms, such as virtual hosting. Although DNS is essential, it has contained vulnerabilities and is the target of many attacks. The greatest problem of basic DNS is the lack of authentication, which allows an attacker to hijack a domain name using forged DNS messages or responses. DNSSEC provides authenticated responses to DNS queries, giving the user proof of domain ownership.
The DNS protocol is also a natural amplifier for distributed denial-of-service attacks, as an attacker can spoof the victim’s IP address in a DNS query, causing the DNS server to send unsolicited traffic to the victim. Unfortunately, migrating to DNSSEC is unlikely to address this issue.
Another DNS-related problem is the detection of botnets. When malware infects a computer, it communicates with a botnet command-and-control server to receive instructions. DNS may be used in this communication. DNS is an attractive communication channel for attackers because it is one of the few protocols likely to pass through firewalls and whose payload remains unchanged. Attackers set up malicious domains for this purpose, and defenders attempt to detect them. The most common defence mechanism is DNS domain blacklists, but their effectiveness is difficult to evaluate. This blacklist-based defence can also be extended to other command-and-control channels. Note that DNS is not the only protocol vulnerable to amplification attacks; NTP is also commonly abused.
Routing (advanced)¶
Another attack-related data source is routing information. Incidents involving BGP routing infrastructure have been studied, but many recorded cases are due to human error. Malicious BGP hijacks have been documented, but they require such significant effort from the attacker that they do not appear to be worthwhile.
Application logs: web server logs and files (advanced)¶
Application logs document the operation of a specific application and thus serve as a data source. Their key advantage over system logs is their similarity to reality and the precision and accuracy of the information they contain. Application logs were originally created for debugging and system administration, and are therefore textual and understandable. Applications can share log files via the Syslog infrastructure. For example, the auth.log file stores user connection information regardless of the mechanism used.
Web server logs (advanced)¶
Web server and proxy server logs are a valuable data source (Common Log Format, CLF; Extended Common Log Format, ECLF). The format is a de facto standard in, for example, Apache web servers. It is very simple and easy to read, providing information about the request (the resource the client attempted to access) and the server’s response code. For this reason, it has been widely used in intrusion detection systems. Its main limitation is the lack of information about the client system, as the log file is local to the server generating it.
Because server logs are written only after the server has responded to a request, an attack has already occurred by the time an IDPS sensor receives the log data. This data source therefore does not meet the requirements of intrusion detection and prevention systems; instead, the IDPS must be connected directly to the data stream in order to block or modify requests.
Files and documents (advanced)¶
Another source of application-level data consists of documents produced by certain applications. Rich document formats (e.g. PDF, files of office programs, rich HTML in emails) are also an opportunity for attackers to embed malware within them. When such documents circulate over networks or email, they leave traces that may reveal embedded malicious code, such as macros or javascript.
Parsing data from documents, whether simple, like TLS certificates, or complex, like PDFs, is challenging. This also presents an opportunity for attackers, as different interpretations can be derived from the same document, leading to vulnerabilities and malware. Nevertheless, rich document formats are here to stay. For this reason, comprehensive (and complex) specifications, like HTML5, must be written with great care to ensure unambiguous interpretation. This reduces opportunities for attackers in the specification itself.
The use of documents as data sources is increasingly important for malware detection.
System and operating system kernel logging (advanced)¶
Operating systems typically maintain logs for debugging and accounting purposes. Most system logs are not sufficient for intrusion detection because they lack the required precision. For example, the Unix logging system records only the first eight characters of commands entered by users, without the path. This makes it impossible to distinguish between commands with the same name but different paths, or between long command names.
Kernel logs now focus on monitoring internal operating system operations and are close to the hardware. The term endpoint protection is often used for this category and has become common for antivirus engines. This highlights the challenge of protecting not only the operating system but also applications, such as browsers and email clients, which may execute untrusted code from external sources.
Syslog (advanced)¶
Syslog provides a general logging infrastructure that serves as an effective data source for many purposes. The original source of logging is the Syslog protocol, which was introduced in BSD Unix. The current specification of Syslog is RFC 5424.
A Syslog entry is a timestamped, text-based message from an identified source. It contains the following information, in this order:
- Timestamp. The date and time of event creation, with one-second precision.
- Host name. The name of the device generating the log. This may be a name, an IP address, or localhost.
- Process. The name of the process generating the log.
- Priority. The class and severity of the log message, calculated according to a standard formula.
- PID. The process identifier of the process generating the log.
- Message. A message qualifying the information, written in 7-bit ASCII by the developer of the application.
Syslog aggregates the information into different files, usually under the /var/log/ directory on Unix systems.
Syslog is also a protocol operating over UDP/513. This facilitates transmission, as UDP tolerates difficult network conditions and can lose a few packets without breaking the whole.
Syslog is extremely useful because it is text-based. Many heavy SOC implementations rely on Syslog to centralise both events and alerts.