Security of Distributed Systems¶
A distributed system is a collection of computing, storage, and communication resources (i.e. hardware) located in different places, which together
- produce services that connect dispersed data producers and consumers,
- provide reliable, available, and consistent access to resources, often using replication schemes to handle resource failures,
- enable the impression that the available data, computation, and services originate from centralized and coordinated resources.
Examples include cloud services, peer‑to‑peer networks, and blockchains.
Possible characteristics from the resource user’s point of view may include
- small physical distance to the resource;
- low latency;
- high bandwidth;
- high performance;
- uninterrupted operation;
- tolerance of accidental and intentional disturbances;
- operation does not require knowledge of technical mechanisms.
Important terms:
- Consistency: information intended to be the same is identical in different locations.
- Consensus: the parts of the system share the same understanding of the system state.
- Topology: the structural form of a network — the arrangement of nodes relative to each other in a way that does not depend on physical distance.
- Overlay network: a network built on top of an underlying network (underlay), such as the Internet, and whose topology differs from it.
General properties of distributed systems¶
This concept map gives you an overview of most issues that this module presents, including the advanced parts.
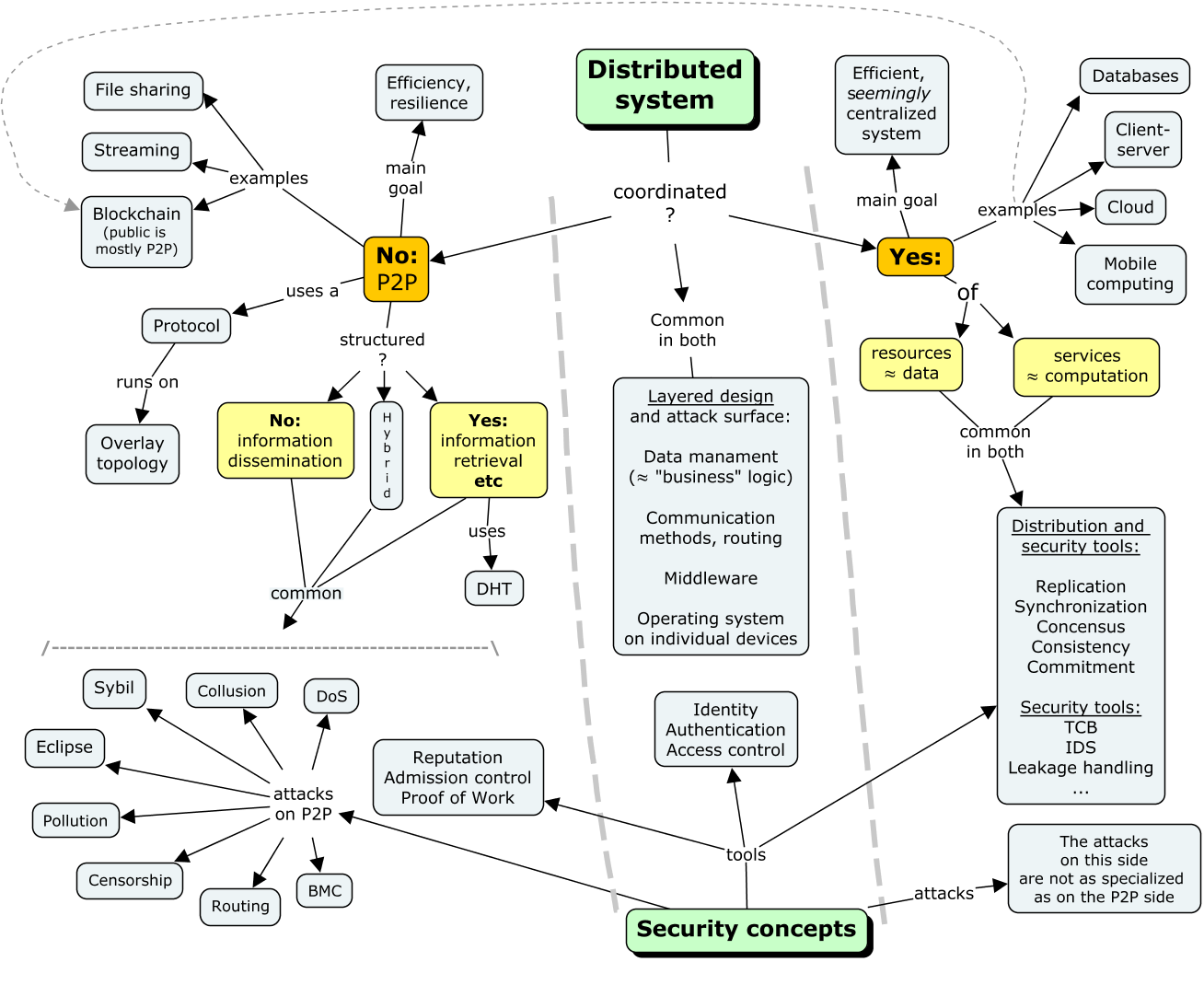
Classification of distributed systems¶
There are various perspectives for characterizing distributed systems. These include defining them
- at the level of resource aggregation, such as P2P and cloud systems,
- at the middleware level, such as publish‑subscribe architectures, distributed object platforms, and web services,
- from the point of view of the services offered by the system, such as databases and ledgers. The latter refers to the application of blockchains.
Distributed systems may be divided into two classes depending on whether their resources operate among themselves or under the control of a coordinating entity:
Peer‑to‑peer networks, or P2P systems, operate without centralized coordination, governed by interactions among the nodes of the network. The rules of interaction are called the protocol. Examples include systems such as Kademlia, Napster, Gnutella, BitTorrent and many other distributed file‑ and music‑sharing and storage systems, wireless sensor networks, and online game systems.
Coordination among distributed resources and services: This is a broad category whose range includes
- client‑server models,
- multilevel service models (i.e. client‑server1‑server2‑…; multitier multitenancy models),
- flexible on‑demand compositions of resources scattered across many locations (various cloud types, Big Data services, high‑performance computing),
- transaction services, such as databases, ledgers, storage systems or a KVS‑store (Key‑Value Store).
The type of coordination can be either
- resource coordination or
- service coordination
Although the type divides systems into two subclasses, in both cases coordination takes place through communication and services. The goal is a seemingly centralized system in which such properties as causality, task ordering, idempotence management, and consistency are ensured. Literature has separate definitions for client-server systems, cloud services, mobile computing, distributed databases, etc., but offering virtually centralized and coordinated behavior is a common feature.
The architecture of both peer‑to‑peer systems and coordinated systems is typically a combination of several layers. At the lowest level, the resources of a given device (memory, computation, storage, communication) are accessed through primitives of that device’s operating system. Distributed services, such as naming, time synchronization, and file systems, are assembled through the interaction of various components and services operating on individual devices. Higher layers build on the lower layers and services, offering additional functions and applications. Middleware provides the interactions at each layer of the distributed system. Various communication styles are used: message passing, remote procedure calls (RPC), distributed object platforms, publish‑subscribe architectures, and the enterprise service bus (ESB). The degree of distribution and coordination may vary in each layer, resulting in hybrid compositions. Public blockchains, such as cryptocurrencies, are uncoordinated and thus peer‑to‑peer, whereas private deployments also exhibit coordination, often beyond mere access restriction.
Later sections in this module introduce
This module focuses on producing security in a distributed system. Another perspective is using distribution itself to produce security. Examples include distributed key storage instead of a centralized key vault, or using virtual machines for partitioning and isolating resources and applications. This perspective also arises because security mechanisms in distributed systems operate naturally when resources are distributed, which in turn enables the use of distribution as a security mechanism (with blockchains as the most prominent example). The topic also relates to the motivation for studying this module: the security mechanisms of distributed systems differ in some respects from those in traditional information systems.
Structuring the attack surface¶
At an abstract level, a distributed system typically includes four basic mechanisms. The attack surface can be structured according to these.
The information flow allowed by access control among the data items injected into the system. This concerns the content of data and how some data modify others — e.g. in blockchains or in the chain of chunks of streamed content — whereas the next mechanism (#2) does not examine the “inside” of the data.
Access control in a distributed system may need to be divided into two concepts: access control and admission control. The former corresponds to its meaning in general cybersecurity. The latter is a possible preliminary phase especially in P2P scenarios, including accepting a user or resource as a member. This resembles the authorization by which users are admitted into an information system but may involve adjustments based on earned or lost reputation, which in turn resembles adjusting a role in an RBAC system. Each object in a distributed system — resource, service, user, or data item — is identified with a physical or logical identity, set either statically or dynamically. Managing identifiers is important for preventing tampering and various other problems. Access control is discussed in more detail in another module.
Data transfer to distributed resources and between them.
This includes routing, message passing, resource interaction in publish‑subscribe practices, event‑based triggering of responses, as well as threats in the middleware stack. A typical example is a man-in-the-middle attack. General threats to communication are discussed in another module.
The resource coordination scheme, which determines e.g. where data transfer should occur so that distribution is meaningful.
This includes synchronization, replication, view changes, time/event ordering, linearizability, consensus, and transaction commit.
Data management, which supports desired applications such as web services, transactions, databases, storage, ledgers, control, and computation.
The usual “C, I and A” apply to every phase and interface of the managed data lifecycle. It is worth recalling that confidentiality (”C”) is threatened by side channels and covert channels (the latter being two‑way, the former leakage). Availability (”A”) concerns include delays and denial of access to data. A special integrity (”I”) consideration is the consistency of information as observed by the participants, which exists in various degrees.
From the list we see that the distinctive threats of distributed systems relate most strongly to #3 and to some extent #4. Coordination is discussed in advanced form later.