Applied cryptography – Introduction¶
One of the fundamental components of information security is cryptography. It is much more than encryption. Multiple disciplines underpin it besides mathematics. Prominent among these—indeed, following from the foundations—are theoretical computer science as well as software and hardware engineering. In addition, the practical security of algorithms requires usability and careful design of application programming interfaces (APIs). Because the foundation is so broad, few people fully understand all aspects. This creates gaps
- between theory and practice,
- between design and implementation, and
- between implementations and the developers who use them.
These gaps lead to vulnerabilities. It is rare for standardised, widely used cryptographic algorithms themselves to fail when used correctly. More commonly, cryptography is broken due to indirect causes. These include incorrect use of API libraries, poor key management, insecure composition of basic algorithms in complex systems, or side-channel leakage. Theory is covered in this module only to the extent needed to understand these phenomena. More theoretical content is provided in later courses such as Cyber Security 2 and Cryptography Engineering. The short cryptography theory module in this material introduces some topics by way of examples.
Crypto algorithms, systems, and protocols¶
Algorithms are at the core of cryptography. Below, they are grouped into primitives, sometimes also referred to as schemes or cryptosystems. For example, public-key encryption, a PKE scheme (public key encryption), consists of three algorithms: key generation, encryption, and decryption. When consulting different sources, you will notice variation in terminology. The terms algorithm, scheme, primitive, and even protocol overlap and are sometimes used interchangeably. This subsection presents one classification, without taking strong positions on how cryptographic algorithms are used in actual communication protocols.
Before diving into algorithms and protocols, it is worth remembering that their ultimate purpose is to reduce the problem of securing large volumes of data and transactions to the problem of protecting keys of only a few hundred bits.
Basic concepts¶
The idea of ciphering, i.e. encryption, is simple: the sender “locks” a message with a key, and the recipient unlocks it with the same key, which may be, for example, a 128-bit string. Others cannot determine the message because they do not have the key, and the locking algorithm is sufficiently complex that the key cannot be guessed and the lock cannot be broken within any reasonable time.
The sender and recipient may also be the same entity, storing a message—or data—for later use in such a way that others cannot access it. A file may effectively become a message if malware transmits its contents over a network. Instead of individuals or directly used devices, the parties may also be, for example, routers within a network.
A general principle, also applicable to mechanical locks, is that the algorithm itself cannot be assumed to be secret—only the key is secret. This is Kerckhoffs’s principle from the 19th century, which became standard in cryptology in the 1970s. If the same key is used for both locking and unlocking, the system is called symmetric; otherwise it is asymmetric. In the digital domain, asymmetry is possible through discrete mathematics, and in such systems the key used in one direction may be public. The corresponding key used in the opposite direction is called the private key.
In addition to key management, algorithms used for encryption, decryption, signing, and signature verification require hash algorithms and cryptographically strong random number generators. Together, these comprise essentially the full range of cryptographic algorithms. Random number generators are included because they are essential for generating good keys. Key management itself is not included, as it primarily makes use of cryptographic techniques rather than constituting an algorithm.
How cryptographic strength is achieved¶
A cryptographic algorithm should produce “cryptic” bit strings—ones from which unauthorised parties can derive no useful information. An attack against a cryptographic algorithm is called cryptanalysis or breaking the system. What constitutes breaking depends on the goals and type of the algorithm: for example, whether the aim is to recover the plaintext message or also the key used for encryption. There are many attack methods, but these are left for later sections. At this stage, it is still useful to understand how the attacker’s task is made difficult.
Encryption algorithms rely on two fundamental ideas, commonly expressed as “diffusion and confusion”. These refer to techniques for hiding the redundancy (repetition) of the plaintext when it is transformed into ciphertext. Confusion obscures the relationship between plaintext and ciphertext, typically by substitution. Diffusion, on the other hand, spreads the influence of plaintext bits across the ciphertext using permutations. Both operations are reversible, so decryption is possible even when these operations are repeated—i.e. iterated—over multiple rounds. Iteration must alternate the operations, since two consecutive permutations or substitutions alone would not increase complexity significantly.
These principles are most clearly seen in block ciphers, where the algorithm is applied to fixed-size blocks of data. Such a cipher is a function that, given a key, maps each n-bit input to another n-bit output. Expanding the output would waste space, while reducing it would make the function non-invertible. Compression before encryption is a separate matter—and often recommended, as it reduces plaintext redundancy. A typical block size n is 128 bits.
The accompanying figure demonstrates a simple block cipher applied to a five-character plaintext. The key here can be interpreted as a tuple (2-5-4-1-3, 1, 3, 2). The first component specifies a permutation (one of 120 possible), the next two specify shift values, and the last specifies the number of rounds.
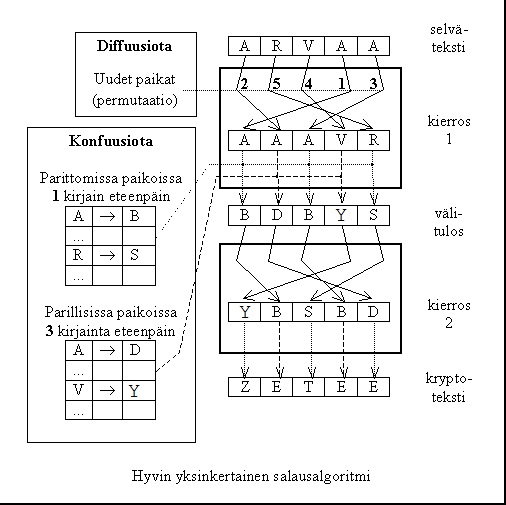
When encrypting with a block cipher, one block of data is always processed through the full algorithm at a time. Depending on the mode of operation, the input may include more than just plaintext—or not consist of plaintext at all.
Classification of primitives¶
In cryptography, as in other fields, primitives can be considered the fundamental building blocks from which everything else is constructed, but which cannot themselves be constructed from one another. The following provides one possible classification of cryptographic primitives.
- Unkeyed:
- hash functions (e.g. MD5, SHA-*). Basic idea: if the receiver computes the hash of a message and obtains the value the sender claims, the message has not been altered in transit. The basic attack model is finding two messages with the same hash.
- one-way functions, which may be bijective but cannot be inverted without a trapdoor. A key example is exponentiation modulo a prime, which underlies the Diffie–Hellman protocol.
- random sequences, i.e. true random numbers that cannot be predicted from previous outputs, typically based on physical phenomena.
- Symmetric (same key in both directions):
- symmetric encryption: block ciphers (e.g. AES, DES, Blowfish, IDEA, Speck; used in modes such as ECB, CTR, CBC, OFB, GCM) and stream ciphers (e.g. SNOW 3G, ChaCha, A5, RC4),
- keyed hash functions (MACs, message authentication codes; e.g. HMAC, CBC-MAC, CMAC): these ensure not only integrity but also authenticity of the message source,
- pseudorandom sequences: generated from a secret seed value; the key property is high entropy (unpredictability),
- authentication primitives (password-based, including one-time passwords).
- Asymmetric (public/private key pairs):
- encryption with a public key (evaluation of a one-way function), decryption using the trapdoor (private key). Examples: RSA, Rabin, ElGamal, McEliece, elliptic-curve cryptosystems, NTRU,
- signatures using a private key (usually applied to a hash), verification with a public key,
- authentication primitives (challenge–response schemes, especially zero-knowledge proofs).
The naming of certain mechanisms as primitives and the boundaries between categories are not strict descriptions of reality, but rather conceptual tools to help manage complexity. Here, the notion of a primitive is broader than that of an algorithm; for example, authentication mechanisms are often protocols rather than algorithms or even schemes. The classification is expanded further later, when encryption is combined with message authentication.
One-time pad¶
This subsection introduces the one-time pad, a historically and theoretically important but impractical cryptosystem. The idea is already illustrated in Example 1, but the presentation also leads into other topics.
The bitwise operation XOR (exclusive OR) is usually denoted by ⊕, but here it is written simply as +. Thus, 0+0 = 1+1 = 0 and 0+1 = 1+0 = 1; that is, addition modulo 2.
Example 1. Let the message (plaintext) be the bit string p = 1010110… and the key k = 0110101…. The ciphertext c is computed bitwise as c = p + k = 1100011…. The plaintext can be recovered by XORing again with the key:
c + k = (p + k) + k = p + (k + k) = p + 0-string = p.
If the key k is truly random, e.g. generated by coin tossing, this is a one-time pad. It (and its variants) is the only encryption scheme that achieves perfect confidentiality—it cannot be broken even with infinite computational power. The key must be random, as long as the message, and used only once.
However, the one-time pad provides only confidentiality. It does not provide integrity, nor does encryption alone generally ensure integrity. These aspects are related. An attacker cannot deduce anything about the plaintext (other than its length) without the key, since any ciphertext could correspond to any plaintext with an appropriate key. Conversely, the legitimate receiver cannot detect modifications to the ciphertext. An attacker could alter the message arbitrarily or, if they know part of its structure, deliberately change specific parts (e.g. numerical values) without detection.
A crucial requirement is that the bits of the key must be independent. This makes the scheme impractical, mainly because the key must be distributed securely in full length to the recipient. Therefore, despite its information-theoretic security, the one-time pad is used only in highly specialised contexts, such as diplomatic or military communication.
The XOR operation itself, however, is widely used, both as part of block ciphers and as the core mechanism of stream ciphers. Stream ciphers differ from the one-time pad in that the keystream is generated algorithmically from a shorter fixed-size seed.
Hash functions¶
“Fingerprints” of data¶
A checksum is a special case of a hash function, which is distinct from “compression”, where the original data can be recovered either exactly (e.g. ZIP, GIF) or approximately (e.g. JPEG).
A familiar example of a checksum is the final character in a personal identification number, calculated from preceding digits. Similar mechanisms are used in bank transfer reference numbers and IBANs, which include check digits to detect input errors.
A simple checksum could, for example, be calculated by summing digits and taking the last digit of the sum (similar to a parity bit). In practice, checksum algorithms are more complex. For example, CRC (Cyclic Redundancy Check) adds bits to a block such that it becomes divisible by a fixed value. If the receiver cannot verify this, the data has been altered.
Cryptographic hash functions¶
To defend against active attacks, hash functions must provide cryptographic security. This means, for example, that malware cannot modify a file in such a way that it produces the same checksum as the original—something trivial with CRC. Cryptographically secure hash functions make it computationally infeasible to find two different inputs producing the same hash. For an n-bit hash, this typically requires on the order of 2^(n/2) attempts, due to the birthday paradox.
While integrity checking is important, a major application of hash functions is in digital signatures, where hashes serve as essential supporting components. Hashes are also used repeatedly in protocols, in key derivation, and in blockchain systems. Iteration means applying the hash function repeatedly to its own output.
Another critically important use is storing passwords not in plaintext, but as one-way hashes.
Hash functions can also be combined with a key. If the key is shared between two parties, the resulting keyed hash (a MAC, message authentication code) allows the receiver to verify both integrity and authenticity. This is a common technique in protocols such as IPsec.
On the one-way nature of hash functions¶
The purpose of a cryptographic hash function is to produce a “digest” of a message that represents the whole message in the sense that it is difficult to find another message with the same digest. Since the digest is only a few hundred bits long while the message may be arbitrarily long, there is obviously an astronomical number of messages with the same digest. The key point is that none of them can be found in practice. This is sometimes emphasised by calling such functions one-way hash functions. In practice, terms such as digital fingerprint or message digest (MD) are also used.
The required one-way property of a hash function H means that given a digest value h, it should be computationally infeasible to find an input x such that H(x) = h. Often a stronger requirement is imposed: it should be infeasible to find any pair of distinct inputs that collide (i.e. produce the same hash), either for arbitrary h or (in a weaker form) for a given input x to find another input y ≠ x such that H(x) = H(y). Any collision may be dangerous, as it can potentially allow an attacker to replace a signed message with another one undetected.
A hash algorithm is always deterministic: it produces the same output for the same input and contains no randomness. However, in theoretical security analyses, hash functions are often modelled as random functions. This is known as the random oracle model. The idea is that the oracle produces “random” outputs but consistently returns the same answer for the same query. In this model, the attacker cannot exploit any internal structure of the hash function. This is theoretically a limitation, but in practice the results have been effective. In more advanced cryptology studies, you will encounter other types of oracles as well.
Map¶
The diagram below summarises and organises the key points about hash functions discussed above. Some topics are covered in more detail later, such as MACs, authenticated encryption, and protocol applications.
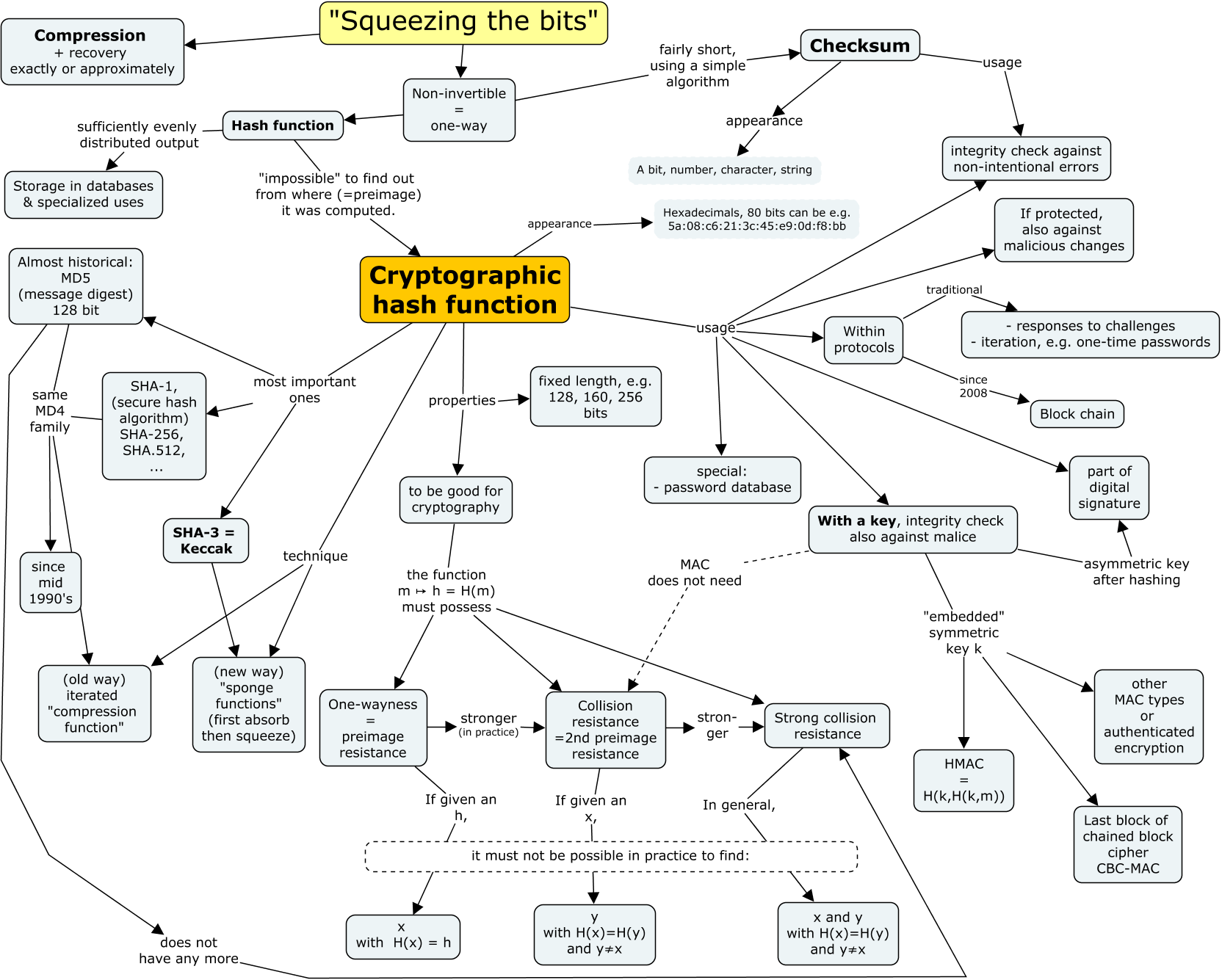
Note on the accessibility of concept maps.
Block ciphers¶
Algorithms¶
There are hundreds of encryption algorithms, and dozens are in common use. Anyone can devise their own, but this is not advisable: even experienced researchers have often found their designs broken by others. The theoretical security goal of a block cipher, however, is relatively simple: it should realise a key-dependent permutation over n-bit strings that is indistinguishable from a random permutation.
If the key is also n bits long, there are 2n possible ciphers, one for each key. Each should resemble a random permutation, of which there are many more: (2n)! possibilities. This type of definition belongs to formal security analysis; in practice, a cryptanalyst focuses instead on how differences in plaintext propagate through the algorithm.
The earlier illustrative algorithm shows how many block ciphers are constructed: through repeated substitution and permutation so that the plaintext becomes increasingly “scrambled”. Such designs can be strengthened by modifying the key across rounds and mixing intermediate results more thoroughly. This is the general idea behind DES (Data Encryption Standard), one of the most well-known algorithms of the late 20th century. It splits a 64-bit block into two 32-bit halves and processes them using the Feistel structure.
DES is no longer considered secure due to its short 56-bit key. It was extended by applying it multiple times (Triple DES), but this is also no longer approved for general use. According to NIST guidance, it has been disallowed for new encryption since the beginning of 2024, except for decrypting previously stored data.
Its successor is AES (Advanced Encryption Standard), originally called Rijndael. AES uses a block size of 128 bits and key lengths of 128, 192, or 256 bits, with 10, 12, or 14 rounds respectively. It also relies on substitution and permutation, though its detailed structure is covered in more advanced courses.
Due to its key sizes, AES is expected to remain secure well beyond 2030. It is widely implemented across platforms and has no known fundamental weaknesses, although some implementations may be vulnerable to side-channel attacks. Other block ciphers may still be useful in constrained environments; for example, Speck is designed for such cases.
Modes of operation (advanced)¶
This section introduces two modes of operation for block ciphers, CBC and CTR. A third mode, GCM, will be presented later, when message authentication is also included. We begin, however, with ECB, which is also a mode.
To begin with, one must realise that a block cipher can be used in a straightforward way by encrypting each plaintext block independently. This is called the electronic codebook (ECB) mode, and it should only be used for very short messages. The key issue is that the same plaintext block should not be encrypted twice with the same key, at least not frequently. Such repetitions would always produce the same ciphertext block, allowing an attacker to build a reverse codebook. An extreme example would be a remote text input system (such as a form) where each keystroke is encrypted and sent to a server and then echoed back. A reverse codebook could be constructed quite quickly using simple statistical analysis. For example, in English, the most common ciphertext block would correspond to “E”, the second most common to “T”, and so on.
To prevent codebook attacks, encryption must depend on how each character or block is positioned relative to others. This ensures that even a single bit difference in a block produces a completely different ciphertext block.
The simplest additional input that can be provided to the cipher, besides the plaintext block, is its position in the sequence. Instead of allocating separate space for a counter, its value is XORed bitwise with the plaintext block before encryption. The receiver XORs the same counter value with the decrypted block.
The above outlines the idea of the counter mode, which will be formally described later in this section. Another approach is to incorporate bits from neighbouring blocks, again using XOR. Reasoning through character-by-character encryption leads to three conclusions: (1) the information should be taken from previous blocks rather than future ones; (2) using all bits of a block is better than only some; and (3) to ensure that even the first block is not repeated from earlier encryptions, additional input is required. This additional input is called the initialisation vector (IV). It must be communicated to the receiver (in plaintext) so that decryption is possible. Although the IV is not secret, it must differ for each encryption instance. Randomness suffices, as long as it is of sufficient quality.
This leads to the CBC mode (cipher block chaining). A final design choice is needed: (4) chaining must use the previous ciphertext block rather than the previous plaintext block. Using plaintext blocks would weaken the system similarly to ECB mode, as each ciphertext block would depend only on two consecutive plaintext blocks instead of propagating influence more broadly.
The CTR mode (counter mode) applies the IV concept by starting the counter from the IV rather than from 1. A significant difference compared to the initial intuition is that the plaintext is not fed into the block cipher at all. Instead, the cipher encrypts successive counter values (IV + counter), producing a sequence of pseudorandom blocks, which are then XORed with the plaintext blocks. Even though the IV is not secret, its random bits combined with the encryption key produce a keystream that is effectively unpredictable. This makes CTR mode a practical approximation of the one-time pad. CTR mode thus “extends” the key.
This approach has practical advantages: encryption and decryption can be parallelised, and arbitrary portions of the message can be processed independently.
Stream ciphers¶
In stream encryption, ciphertext is obtained by XORing the plaintext with a pseudorandom sequence, called the keystream, which is generated from a fixed-size key agreed upon during key exchange (cf. the one-time pad, where each key bit must be generated independently). One way to generate such a sequence is to repeatedly encrypt a fixed input using a block cipher and feed the output back as input. This corresponds to the Output Feedback Mode (OFB). Alternatively, CTR-like constructions can be used.
Although stream encryption can be implemented using block ciphers, this approach is not used when high speed is required. Traditionally, fast stream ciphers have been implemented using linear feedback shift registers (LFSRs) in hardware. The details of LFSRs are beyond the scope of this course.
Message authentication codes (MAC)¶
A message transmitted over an insecure channel may be modified in transit, even if encrypted. If a cryptographic hash is included, an attacker can simply recompute it for the modified message. This attack is prevented if computing the hash requires a shared secret between sender and receiver. This is the principle of the message authentication code (MAC), as mentioned earlier.
Formally, a MAC scheme consists of three algorithms: KeyGen, Tag, and Verify. First, a key is generated. Then a MAC value (tag) is computed from the key and the message. Verification involves recomputing the MAC and comparing it with the received value. If they match, the message is both intact and authentic—i.e. it originates from a party that knows the key.
The formal security goal of a MAC is strong unforgeability under chosen-message attack. This means that an attacker who does not know the key cannot generate a valid (message, MAC) pair, even if they have seen many such pairs and chosen the corresponding messages.
MAC schemes can be constructed from hash functions or block ciphers. A simple approach is to hash the concatenation of key and message, but such constructions have vulnerabilities. A more robust construction is HMAC, where the hash function is applied twice. If k is the key and x the message, HMAC is defined as H( k, t1, H( k, t2, x)), where t1 and t2 are padding values ensuring proper input length. The comma-separated inputs are concatenated into a bit string.
Authenticated encryption (AE) (advanced)¶
Previously, MACs were introduced by noting that confidentiality alone does not guarantee integrity. When security requirements mention confidentiality—or encryption explicitly—they usually also imply authenticity. Adequate guarantees of authenticity and integrity can be combined with encryption in three ways:
- encrypt first, then compute the MAC (MAC over the ciphertext)
- compute the MAC first, then encrypt (MAC is also encrypted)
- perform encryption and MAC simultaneously
All approaches increase the length of the output due to the MAC. Option 1 is conceptually the clearest, but both 1 and 2 require separate keys for encryption and MAC to achieve strong security. This has motivated the development of option 3. Another advantage of option 3 is performance: in options 1 and 2 the message is processed twice, whereas in option 3 only once.
All these approaches are referred to as AE schemes (authenticated encryption). Often, systems also authenticate additional data that must remain unencrypted, such as headers required for message routing. Such systems are called AEAD (authenticated encryption with associated data).
The most important practical AEAD scheme is AES-GCM, where the AES block cipher is used in Galois/Counter Mode. This mode adds authentication to AES and handles associated data. In addition to plaintext and associated data, it takes a nonce, which may be random but must above all be unique. (The term derives from “nonce word”, meaning “for one occasion”.) A counter can serve as a nonce and is useful for tracking the amount of data encrypted under the same key. Note that both the nonce and associated data are transmitted in plaintext. AES-GCM is used in approximately 90% of TLS connections on the web.
Public-key systems for encryption¶
Introduction to public-key cryptography¶
A good encryption algorithm performs a transformation that is infeasible to invert without a secret key. Traditionally—and still today—such algorithms handle most protected data. However, modern network applications also require algorithms in which the key is not secret: functions that are easy to compute but difficult to invert even without hidden parameters.
A key example is exponentiation modulo a large prime. Inverting this operation requires solving a discrete logarithm problem, which is computationally infeasible for sufficiently large parameters. This operation is used, for example, in key exchange protocols such as Diffie–Hellman.
Another important case leads to both encryption and decryption. Let n be the product of two large primes p and q, which are unknown. If a number x is squared modulo n (i.e. y = x² mod n), it is infeasible to recover x from y and n alone.
Example: let p = 5 and q = 7, so n = 35. If x = 13, then y = 13² mod 35 = 169 mod 35 = 29. While 29 is not a square as an integer, modulo 35 it corresponds to four square roots (e.g. ±13 and ±8 modulo 35).
If someone knows p and q, however, they can compute square roots modulo each prime efficiently and combine them, yielding all possible candidates for x. If x encodes meaningful data (with redundancy such as language or checksum), the correct solution can be identified. This illustrates that slight non-uniqueness (“4-to-1”) does not hinder decryption.
Thus, the encryption key (n) can be public, while decryption requires additional knowledge (p and q), known as the private key. This asymmetry gives rise to asymmetric cryptosystems. The extra information enabling inversion is called a trapdoor. All public-key cryptosystems rely on such structures.
A related example is RSA, where the trapdoor is also the factorisation of n. For sufficiently large n, factorisation is computationally infeasible. For example, factoring a 1024-bit modulus would take on the order of 10^7 years on a machine performing one million operations per second (though see Key length for updates).
A user can therefore safely publish n and allow others to send encrypted messages, which only the holder of the private key can decrypt. This scheme is known as the Rabin cryptosystem (1979). Breaking it is equivalent to factoring n.
Key encapsulation¶
Public-key algorithms operate on very large numbers and are therefore slow. Applying them directly to large data would be inefficient. Instead, encryption is typically performed as follows:
A random symmetric key is generated and used to encrypt the data using a fast algorithm such as AES. Then, this symmetric key is encrypted using a public-key algorithm. This is sometimes called a digital envelope; the modern term is key encapsulation.
Since symmetric keys are relatively short (a few hundred bits), padding is required to match the input size expected by the public-key algorithm. For example, RSA uses moduli of at least about 1000 bits, so the input must be extended appropriately.
Common public-key encryption systems (advanced)¶
The introduction already presented the ideas of public and private keys and trapdoors, using the Rabin system as an example. While suitably simple, it is not widely used. From the same era comes RSA, the best-known asymmetric cryptosystem, developed by Rivest, Shamir, and Adleman in 1978. Encryption resembles the Rabin system, as it may involve, for example, cubing (instead of squaring in Rabin). Decryption is likewise a single exponentiation. All computations are performed modulo n, i.e. taking the remainder with respect to the public modulus n. RSA operates as follows:
- encryption of plaintext x into ciphertext y: y = xe mod n
- decryption of ciphertext y into plaintext x: x = yd mod n
Thus, RSA keys are:
- public: modulus n and exponent e (encrypt)
- private: exponent d (decrypt)
and the trapdoor consists of the factors of the modulus, two large primes p and q. The system’s creator generates and verifies these, selects a public exponent e (e.g. 3 suffices), and computes the private exponent d. See the example below for how d is computed from e.
Example. Choose primes p = 5 and q = 11, giving n = 55. Let e = 3. Then d is obtained by solving e·d = 1 mod (p−1)(q−1), i.e. 3d = 1 mod 40. This can be done mentally: 3d = 81 works, giving d = 27.
Let the message be m = 13. Then the ciphertext is c = me mod n = 13³ mod 55 = 2197 mod 55 = 52. With sufficient precision, one can verify that cd mod n = 5227 mod 55 = 13.
A naïve exponentiation would produce a number around 2·1046, which is infeasible to compute directly for large inputs. Instead, exponentiation is performed efficiently by expressing the exponent as a sum of powers of two. For example, 27 = 16 + 8 + 2 + 1 (binary 11011), so
c27 = c · c² · c⁸ · c¹⁶
Each intermediate result is reduced modulo n, keeping values manageable. This reduces the number of multiplications significantly.
The security of RSA rests on the fact that the private exponent d cannot feasibly be derived from the public values e and n. In principle, one could factor n into p and q and compute d, but factoring large n is computationally hard. It would suffice to know (p−1)(q−1), since e and d are inverses modulo this value.
RSA key sizes have grown over time from 512 bits to 2048 bits (sometimes 3072). More efficient alternatives exist using more advanced algebra. Increasingly, elliptic curve cryptosystems are replacing RSA. RSA cannot be implemented directly with elliptic curves, but related systems such as Diffie–Hellman and ElGamal can, and this is now the dominant approach.
Another algebraic structure uses polynomials and lattices. Systems such as NTRU are promising, particularly because they are resistant to quantum attacks. NIST has standardised post-quantum algorithms such as ML-KEM (key exchange) and ML-DSA (signatures), with others such as FN-DSA and HQC also under development.
Diffie–Hellman–Merkle key exchange¶
Without numbers and formulas, the topic oif this subsection can be explored via Computerphile’s “watercolour video” or the Wikipedia colour diagram.
{kind=link}
The central principle of encryption is that communicating parties need a shared secret key that no one else knows. However, agreeing on such a key is challenging: it cannot be sent securely without already having a key.
The ingenious solution relies on properties of exponentiation and the difficulty of computing discrete logarithms (and was expressed in colour in the above links). Ignoring modular arithmetic for intuition:
Two parties A and B agree on a base g (not secret). Each selects a secret number: A chooses x, B chooses y. They exchange gx and gy. Each then computes:
- A computes (gy)x = gxy
- B computes (gx)y = gxy
Thus, both derive the same shared key.
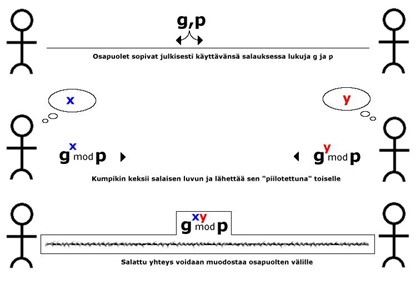
An attacker observing gx and gy would need to recover x or y to compute gxy, which requires solving a discrete logarithm—computationally infeasible for large parameters.
However, this protocol is vulnerable to a man-in-the-middle attack. An attacker C can intercept messages and substitute their own value gz. Then:
- A computes gxz
- B computes gyz
C knows both and can decrypt and re-encrypt all messages, acting as an invisible intermediary.
Therefore, Diffie–Hellman must be combined with authentication (e.g. signatures) to prevent such attacks. When properly authenticated (e.g. via the STS protocol), it becomes a highly secure and widely used building block in cryptographic protocols.
This Diffie–Hellman–Merkle key exchange protocol, first published in 1976, is historically the first public-key cryptosystem.
Digital signatures¶
RSA was developed and patented by Rivest, Shamir, and Adleman. Their original 1978 paper was titled “A method for obtaining digital signatures and public key cryptosystems”. The same technique can be used both for encryption and for digital signatures, simply in reverse. Other public-key encryption schemes (notably ElGamal) can also be adapted for signatures, although the details differ significantly.
Today, electronic signatures can be created using banking credentials. While these have the same legal effect as handwritten signatures, conceptually they differ from cryptographic digital signatures. It is important to keep this distinction in mind.
A cryptographic signature is conceptually simple. The signer computes a mathematical function of a message or document using a private key known only to them. Anyone else can verify the signature using the corresponding public key. Due to the properties of the function, forging signatures is computationally infeasible. Thus, no one else can create valid signatures or alter signed messages without detection.
Bank-based signing systems provide legal authenticity: only the signer is deemed responsible. However, the bank controls the underlying data and mechanisms. Trust is therefore placed in institutions rather than purely in mathematical properties. True cryptographic signatures—such as those using personal private keys in identity cards—have not become as widespread in daily use, even though they are widely used behind the scenes in systems, including banking authentication.
Thus, the earlier statement that signatures are simple is only partially true. In addition to the mathematics, reliable public key management is required to link public keys to identities. This leads to trust structures similar to those discussed earlier, encapsulated in the concept of PKI (public key infrastructure).
How is a digital signature created and verified in RSA? Suppose Alice has a public key (n, e) and knows the private exponent d (derived from e·d ≡ 1 mod (p−1)(q−1) after generating primes p and q). She signs a message m by computing:
s = md mod n
When she sends (m, s) to Bob, Bob verifies:
m = se mod n
If the equation holds, Alice cannot deny having signed the message—unless her private key has been compromised.
In practice, RSA signatures are applied to hashes rather than full messages, for efficiency and security. Thus, Alice computes:
s = (H(m))d mod n
and sends (m, s). The hash is padded to match the modulus size.
Digital signatures in TLS
PKI is covered in more detail later, so this example remains high level. TLS uses asymmetric cryptography for key exchange and authentication—that is, to ensure that each party can trust the identity of the other.
Typically, only the server needs to authenticate itself to the client. For example, when connecting to facebook.com, the user wants assurance that the server is indeed operated by Meta. Without authentication, an attacker could impersonate the site.
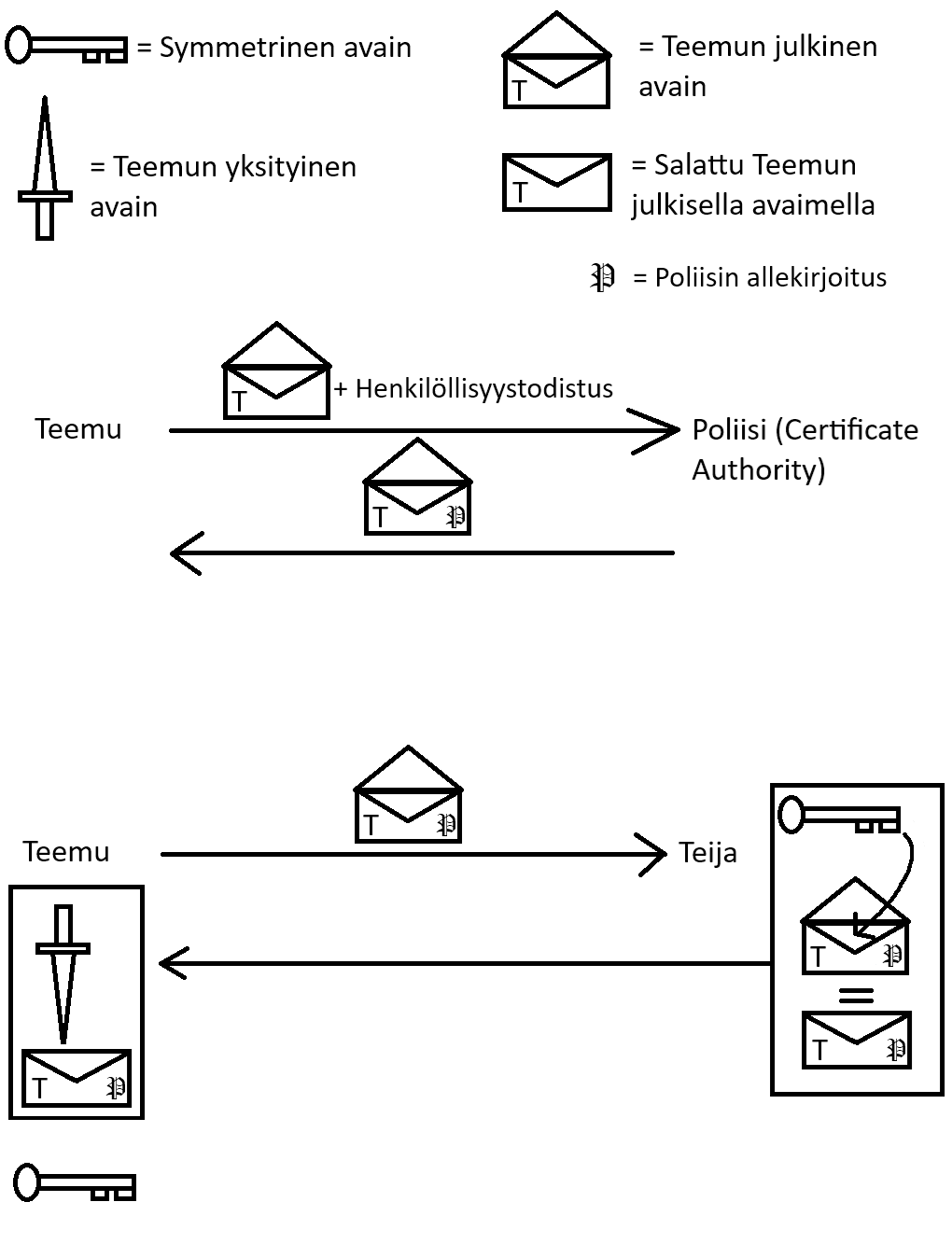
Returning to the earlier analogy: symmetric encryption was compared to a shared lock and key. Now, imagine that Teija must send a key to Teemu but cannot meet him in person. She uses a “signed envelope” analogy:
- Teemu has an envelope (public key) that only he can open (using his private key).
- He obtains a signature from a trusted authority (the police).
- He sends the signed envelope to Teija.
- Teija verifies the authority’s signature and places the key inside.
- Teemu opens the envelope with his private key.
This illustrates the TLS handshake in simplified form, where a certificate authority verifies identities and enables secure key exchange.
Diversity of cryptography¶
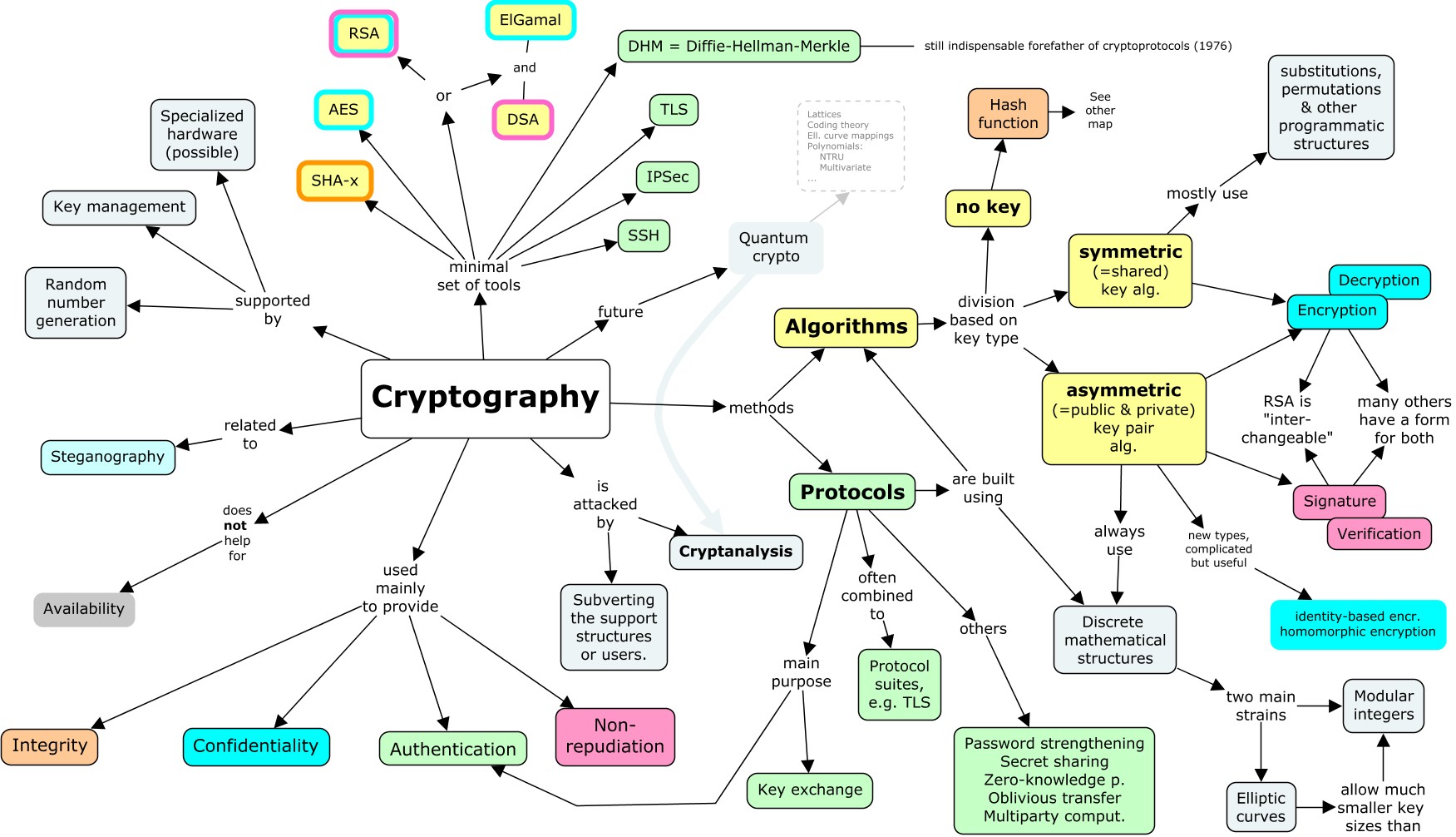
So far, this applied cryptography module has focused on the most important algorithms and schemes used in modern systems. The diagram below also highlights protocols, which are discussed later. Colours are used to link different use cases to algorithm types.
Mathematical research, combined with system-level thinking, continually introduces new approaches that make cryptography applicable in new contexts. Blockchains were already mentioned in the earlier map. In the diagram below, homomorphic encryption refers to “computable ciphertexts”. While it is always possible to combine encrypted data (e.g. addition or multiplication), the result typically does not correspond meaningfully to operations on the plaintext. The challenge is to preserve structure while keeping data secure.
There is strong interest in fully homomorphic encryption, which would allow computation directly on encrypted data. Similarly, identity-based encryption (where “you are your key”) and many other ideas continue to be explored. The literature reveals that this diagram represents only a small fraction of cryptographic research. Many ideas are not yet standardised or lack production-quality implementations.
This highlights the gap between cryptography in research papers and cryptography ready for deployment.
Even without deep mathematical research, one can build innovative systems by combining well-established primitives with proven security properties. Understanding the basics remains essential for organising these concepts effectively.
Note on the accessibility of concept maps.
Accounting for attacker capabilities¶
In this text, the adversary has remained somewhat abstract, and not all attack scenarios have been explored in detail. Cryptographic theory models attackers based on their capabilities and knowledge. For example, scenarios include:
- ciphertext-only attack (COA)
- known-plaintext attack (KPA)
- chosen-plaintext attack (CPA, CPA2 for adaptive)
- chosen-ciphertext attack (CCA, CCA2)
These models describe how much information an attacker has and how they can interact with the system. Similar models exist for signatures and MACs. Different applications require resistance against specific attack classes.
In practice, attackers vary widely in motivation, expertise, and resources. Cryptographic systems are therefore designed conservatively, assuming attackers may have substantial computational power.
Perfect (information-theoretic) security is generally impractical, as it would require excessive key material, as seen in the one-time pad. Instead, systems aim for computational security by limiting the attacker’s feasible resources.
A typical benchmark is 128-bit security, meaning that breaking the system would require work comparable to brute-forcing a 128-bit AES key. This is currently beyond realistic capability. For perspective, global Bitcoin mining performs roughly 267 hash operations per second, yet brute-forcing such a key would still take about 236 seconds (roughly 1011 years).
Higher security levels (192- or 256-bit) may be desirable for long-term protection, especially considering future advances such as quantum computing or large-scale parallel attacks.
Caution is also necessary when dealing with known weaknesses. Even minor vulnerabilities may be amplified over time as computational power and cryptanalytic techniques improve. However, replacing cryptographic systems can be costly and difficult unless cryptographic agility is built in. As a result, many systems still rely on outdated algorithms until a practical attack forces change.
The role of formal definitions and proofs (advanced)¶
The security analysis of cryptographic systems has reached a level of maturity where, ideally, one should never deploy a cryptographic scheme or protocol without a clearly defined syntax and a precise security proof based on explicitly stated assumptions. Unfortunately, this principle is still often ignored in practice. This leaves room for later analyses, which may uncover flaws or provide evidence of security.
In an ideal workflow, requirements for a new scheme or protocol would first be collected, then the system designed, and security proofs developed alongside it. In reality, development often follows a cycle of design → publication → break → fix. A modified cycle (design → break → fix → publish) was used in the development of TLS version 1.3.
Key length (advanced)¶
As discussed earlier, targeting a 128-bit security level is reasonable, as it provides a sufficient margin in most practical computing scenarios. Another advantage is that it can be achieved efficiently in most applications, except highly constrained environments.
Algorithms and keys have a limited lifespan. Advances in cryptanalysis may render previously secure choices insecure. Additionally, the longer a key is used, the higher the probability of compromise. These factors motivate conservative choices during initial system design.
Achieving 128-bit security raises efficiency concerns, particularly for asymmetric cryptography. For example, achieving equivalent security against factorisation attacks may require a 3072-bit RSA modulus. This is due to the sub-exponential complexity of the best-known factoring algorithms. Such large parameters significantly slow down RSA operations, whose complexity grows roughly cubically with key size.
The same applies to systems based on discrete logarithms in modular arithmetic (e.g. Diffie–Hellman and ElGamal). In contrast, elliptic curve cryptography does not admit similar algorithmic speed-ups for the underlying hard problem. This allows the use of much smaller parameters: a 256-bit elliptic curve suffices for 128-bit security.
The contrast becomes even stronger at higher security levels. For 256-bit security, RSA would require keys of around 15360 bits, whereas elliptic curve systems require only about 512-bit parameters.
Cryptographic agility (advanced)¶
In some systems or protocols, it becomes necessary to replace one algorithm with another of the same type. This may be due to vulnerabilities being discovered (e.g. MD5), the availability of more efficient alternatives (e.g. elliptic curves instead of RSA), or the need to prepare for future technological developments such as quantum computing.
Replacing algorithms is facilitated if the system is cryptographically agile, meaning it has built-in support for switching between algorithms or protocol versions. This capability exists in protocols such as IPsec, SSH, and TLS, which negotiate cipher suites and protocol versions at the start of communication.
However, adding such flexibility can introduce vulnerabilities. Negotiation mechanisms themselves may become attack vectors, as demonstrated by SSL/TLS downgrade attacks, where attackers forced systems to use weaker algorithms or legacy protocol versions.
Cryptographic agility can also increase software complexity, as supporting many algorithms may lead to bloated implementations.
An alternative approach is to fix a limited set of algorithms, as in the VPN protocol WireGuard, which does not support algorithm negotiation or version switching.
In practice, a balanced approach is often preferred: support agility where necessary, but strictly control which algorithms and protocol versions are allowed.
Development of standardised cryptography (advanced)¶
Cryptographic processing of bits should be standardised to enable communication. Standards are developed at multiple levels and by various bodies: internationally, regionally, and within specific industry groups. Some key technologies become standards across several organisations. For example, RSA is standardised as ISO/IEC 9796, IEEE Std 1363-2000, ANSI X9.31, and PKCS#1. These are versions of essentially the same concept at different points in time, with variations in parameter choices and the schemes built around the core algorithm.
From the perspective of computer networks, IETF Internet standards—RFCs (“Request for Comments”)—are particularly important. Many of these are based on or adapted from earlier standards. For example, Netscape’s SSL 3.0 evolved into TLS: first published as RFC 2246, followed by versions 1.1, 1.2, and 1.3 (RFC 4346, 5246, and 8446 respectively, covering the years 1999, 2006, 2008, and 2018).
The most important standardisation bodies in cryptography are the international ISO/IEC and IETF, along with the US-based NIST. Their working methods differ: ISO/IEC operates relatively privately, NIST uses open comment processes and occasionally organises competitions (as for AES and post-quantum cryptography), and IETF participation is open to anyone.
Standardisation bodies are not perfect. A large number of contributors and outputs can lead to fragmentation in cryptography, making interoperability more difficult. There may also be subtle incompatibilities between different versions of algorithms. Even open standardisation processes may fail to incorporate feedback from all relevant stakeholders. Standards may be published prematurely, before their limitations are fully understood or before superior alternatives emerge. Once a standard is in place and no major attacks appear, there may be little motivation to improve it. The history of RSA-based encryption schemes illustrates this well, particularly the limited adoption of its most secure key encapsulation methods.
Standardisation bodies may also be influenced by national or commercial interests. For example, the US NSA was historically involved in the design of the DES algorithm and later contributed to the design of a pseudorandom bit generator (Dual_EC_DRBG), including the selection of critical parameters. In such contexts, transparency regarding stakeholder involvement is crucial. For example, NIST has revised its standardisation processes to increase openness and reduce dependence on external organisations.